⟡ A terminal AI chat interface for any LLM model, with file context, MCP and deployment support.
- Local multi skilled agent with files, clipboard & MCP support
- Project folder scoped - different agent per project
- Host your agent web chat UI (Next.js) from command line in seconds and ready for deployment
- Create a multi-agent cluster with predefind strategies.
- Checkout
- Install
- CLI
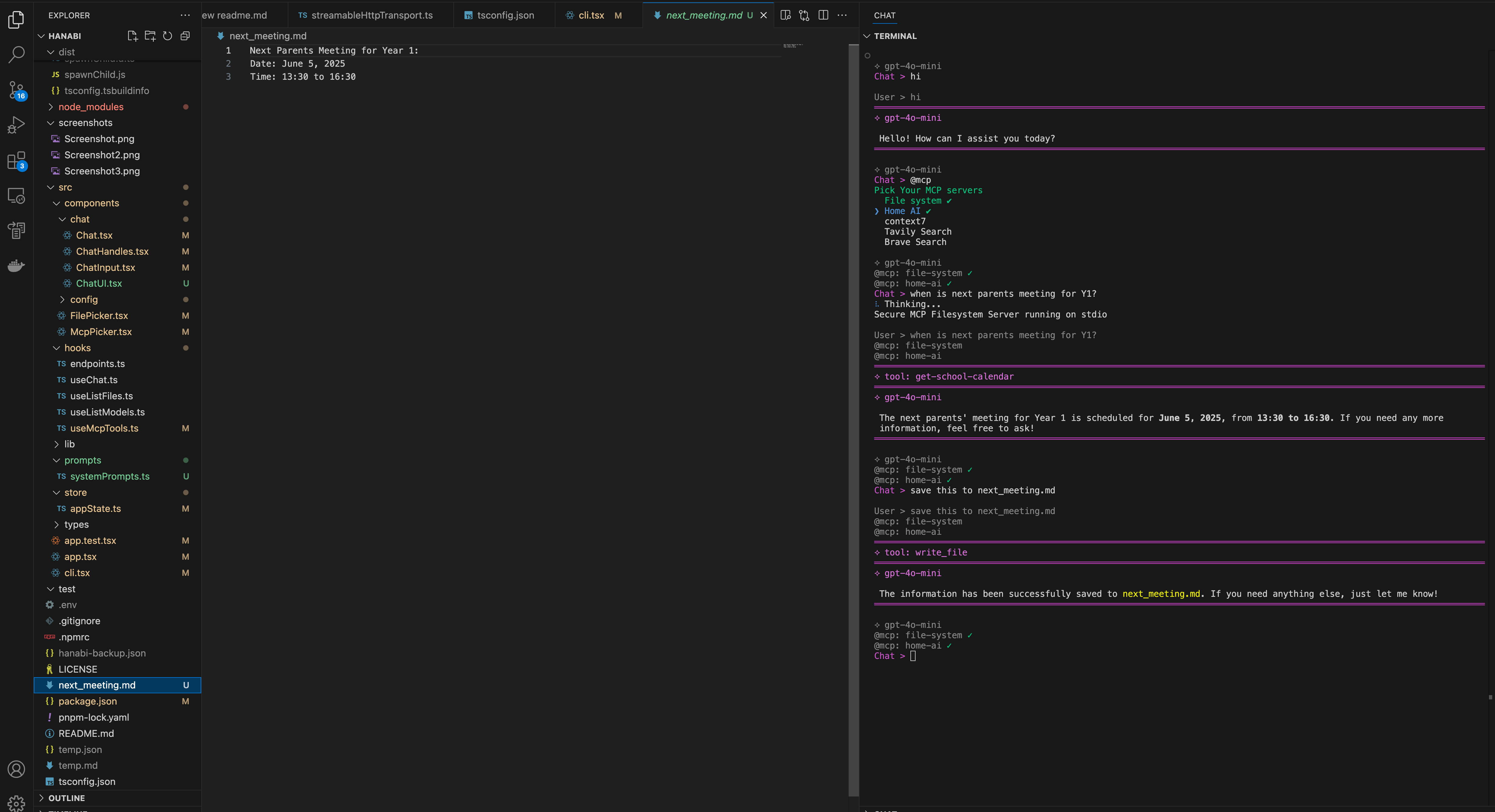
- MCP Servers
- Exclude files
- Local envs
- Custom System Prompt
- Local config file override
- Streaming Mode
- Answer Schema (Deterministic Output Format)
- Web Chat UI Server (with APIs)
- Advanced - Multi Agents System
- TODOs
$ npm install -g hanabi-cliGet Help
$ hanabi --help
Start hanabi chat session
$ hanabi
Reset config file
$ hanabi reset
Ask single question and print result. (Yes Hanabi auto injects today's date and timezone for you as context)
$ hanabi ask "how's the weather tomorrow?"
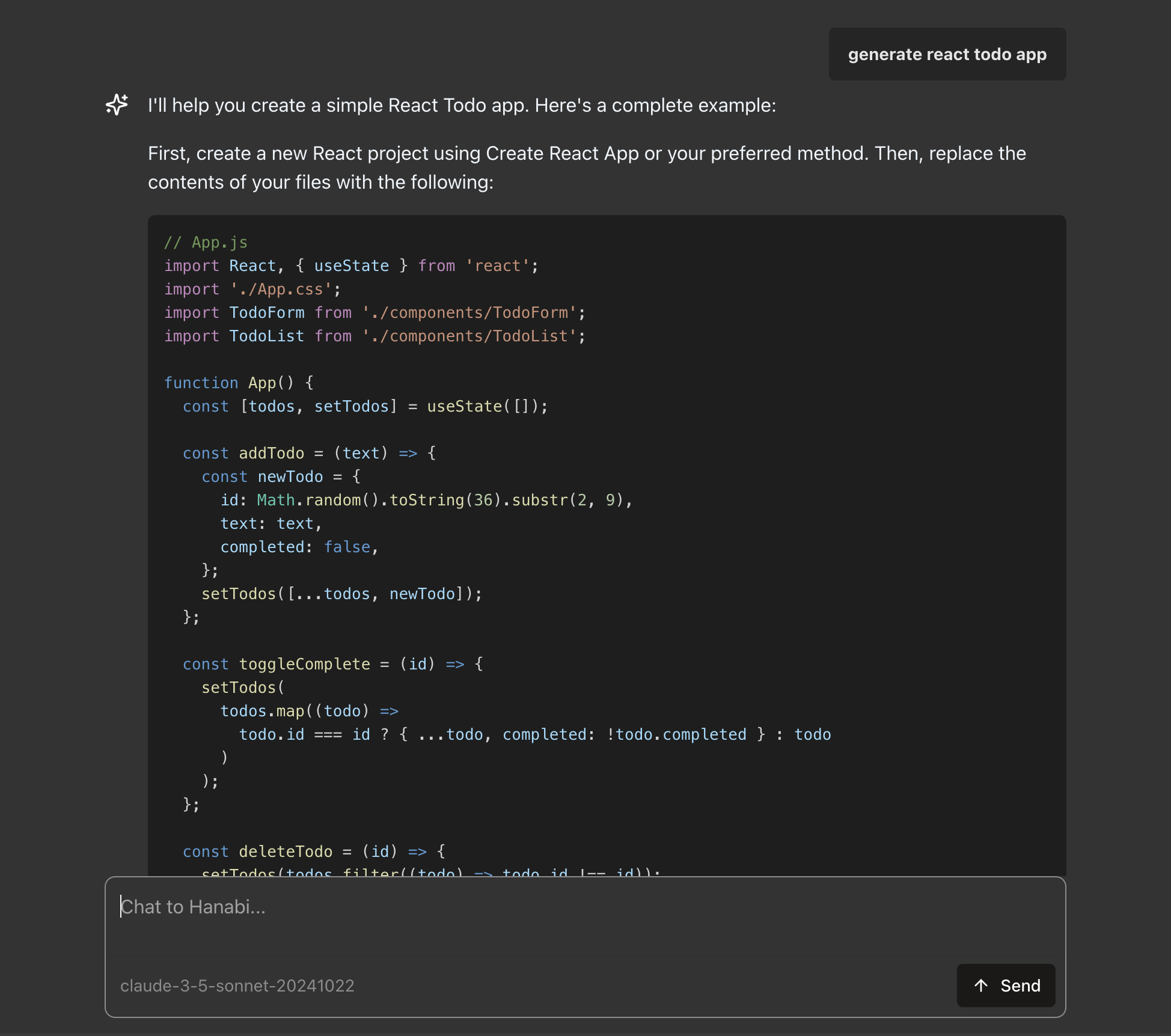
$ hanabi ask "generate a react todo app" > ./todo-app-instructions.md
In your <user home folder>/.hanabi.json, add mcpServers config.
{
"llms": [
// ...
],
"defaultModel": {
// ...
},
"mcpServers": {
"home-ai": {
"name": "Home AI",
"transport": "stdio",
"command": "node",
"args": ["c:/folder/home-mcp.js"]
},
"context7": {
"name": "context7",
"transport": "stdio",
"command": "npx",
"args": ["-y", "@upstash/context7-mcp@latest"]
},
"browser-use": {
"name": "Browser-use automation",
"transport": "sse",
"url": "http://172.17.0.1:3003/sse",
"headers": {
"authentication": "Bearer api-token"
}
},
// npx stdio approach is flaky & slow. highly recommend
// to npm install -g <mcp-server> and use the following.
// see https://github.com/modelcontextprotocol/servers/issues/64
// "file-system": {
// "name": "file system",
// "transport": "stdio",
// "command": "path/to/your/node.exe",
// "args": [
// "path/to/global/node_modules/@modelcontextprotocol/server-filesystem/dist/index.js", "."]
// },
"tavily": {
"name": "Tavily Search",
"transport": "stdio",
"command": "npx",
"env": {
"TAVILY_API_KEY": "your-api-key"
},
"args": ["-y", "tavily-mcp@0.1.4"]
},
// npx is slow! use above recommendation
"file-system": {
"name": "file system",
"transport": "stdio",
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-filesystem", "."]
},
"my-calendar": {
"name": "My Calendar",
"transport": "streamable_http",
"url": "http://172.17.0.1:3001/mcp",
"headers": {
"authentication": "Bearer my-auth-token"
}
}
}
}
To prevent files from being accessed, add globby patterns in the config
All files included in the .gitignore will also be auto excluded.
// <user home folder>/.hanabi.json
{
"exclude": ["certificates", "screenshots/**/*", "passwords/*", "*.pid"],
"llms": [
// ...
],
"defaultModel": {
// ...
}
}
Hanabi supports local dot env files (.env).
You can also add envs field to .hanabi.json.
use file:// prefix URL to inject file content as env variable
Supports only plain text files e.g. *.json,*.txt, *.html etc.
To inject PDF file content into process.env, convert them to text files by using something like pdf2json.
add ALLOWED_ORIGIN env to add cors protection for the API server.
// .hanabi.json
{
"envs": {
"FOO": "bar",
"MY_DOC: "file://./README.md",
"ALLOWED_ORIGIN": "http://localhost:3042"
},
"llms": [
// ...
],
"defaultModel": {
// ...
}
}
If you do not want to store provider api key or any other tokens in .hanabi.json, delete the apiKey fields and save them inside working directly .env instead. Key names are as below. see Providers or
OPENAI_API_KEY=xxx
GOOGLE_GENERATIVE_AI_API_KEY=xxx
DEEPSEEK_API_KEY=xxx
ANTHROPIC_API_KEY=xxx
GROQ_API_KEY=xxx
XAI_API_KEY=xxx
# MCP keys
TAVILY_API_KEY=xxx
Hanabi comes with predefined simple system prompt to show docs on terminal commands and provide date & timezone context. You can provide extra system prompt in hanabi.system.prompt.md at working directory. Use /gen handle or hanabi gen to generate one for you.
Variables are supported via ${VAR_NAME} syntax, they are read from process.env. see Local envs.
example hanabi.system.prompt.md
# act as a polite chat bot collecting user feedback via conversational loop.
## context
Product name is ${PRODUCT_NAME}
## ask user the follwing questions one by one and prints a well formatted report
- What is your name
- How do you feel about our product? (classify answer as "Bad" | "OK" | "great")
- What is your companyYou can copy <user home folder>/.hanabi.json to your working directly (e.g. project level) to override user level config. LLMs are merged by provider name. Use /gen or hanabi gen handle to generate one for you.
Toggle "streaming":true at <user home folder>/.hanabi.json or the one at working directory.
It's quite important for workflow agent to output answer in a deterministic schema, e.g when asking agent to generate API call payload. To achieve that, define answerSchema that's Zod schema compliant in the config file.
-
answerSchemawill be applied in- cli chat answers when @schema handle is active
- cli single question mode
hanabi ask "list top 10 movies in 2023" > output.json - Web UI chat with toggle
- server APIs e.g.
/api/generate
-
Use
/genhandle orhanabi gento generate one for you. -
for more details:
// .hanabi.json
{
"answerSchema": {
"type": "object",
"required": ["answer"],
"properties": {
"reason": {
"type": "string",
"description": "detailed reasoning for the final output."
},
"answer": {
"type": "string",
"description": "the final output without reasoning details. For math related question, this is the final output number."
}
}
},
"serve": {
...
},
"llms": [
// ...
],
"defaultModel": {
// ...
}
}
It's recommended to create a local .hanabi.json for independent chat server
In Hanabi cli, use /serve to start the web server with current context (MCPs & system prompt). This will save serve config to your .hanabi.json.
Use hanabi serve to start the web UI server directly - useful for deployments.
Use apiOnly to disable chat UI.
See server API details
// .hanabi.json
{
"serve": {
"mcpKeys": ["home-ai"],
"port": 3041,
/** name of the agent */
name?: string;
/** disable chat UI and only expose API endpoints */
apiOnly?: boolean;
},
"llms": [
// ...
],
"defaultModel": {
// ...
}
}
You can orchestrade multiple (remote) agents in various strategies or patterns
Please note:
- In the cli chat, use
@agentshandle to activate. - In web UI chat, multi agents mode is always enabled if set in
.hanabi.json- Only the final worker agent's response will be streamed to the UI.
Currently hanabi supports the following strategy types
see
- Use
/genhandle orhanabi gento generate one for you.
// .hanabi.json
{
"multiAgents": {
"strategy": "routing",
/** default false - question with no classification
* will be passed through to routing agent */
"force": false,
"agents": [
{
"name": "calendars",
"apiUrl": "http://localhost:3051/api",
"classification": "school calendar events and UK public holiday"
},
{
"name": "math",
"apiUrl": "http://localhost:3052/api",
"classification": "math problem"
},
{
"name": "api-doc",
"apiUrl": "http://localhost:3053/api",
"classification": "API document"
}
]
},
"llms": [
// ...
],
"defaultModel": {
// ...
}
}
see
- in this mode, chat history is ignored. Each user message triggers a new, independent workflow.
- Use
/genhandle orhanabi gento generate one for you.
// .hanabi.json
{
"multiAgents": {
"strategy": "workflow",
"steps": [
{
"apiUrl": "http://localhost:3051/api",
"name": "process user email into trade instruction"
},
{
"apiUrl": "http://localhost:3052/api",
"name": "trade booking with payload"
}
]
},
"llms": [
// ...
],
"defaultModel": {
// ...
}
}
see
- send user query to multiple agents for different types of tasks in parallel and output aggregated summary.
- Use
/genhandle orhanabi gento generate one for you.
// .hanabi.json
{
"multiAgents": {
strategy: 'parallel',
agents: [
{
name: 'code quality agent',
apiUrl: 'http://localhost:3051/api',
prompt:
'Review code structure, readability, and adherence to best practices.',
},
{
name: 'code performance agent',
apiUrl: 'http://localhost:3052/api',
prompt: 'Identify performance bottlenecks & memory leaks.',
},
{
name: 'code security agent',
apiUrl: 'http://localhost:3053/api',
prompt:
'Identify security vulnerabilities, injection risks, and authentication issues',
},
],
},
"llms": [
// ...
],
"defaultModel": {
// ...
}
}
- include local files in chat
- mcp support
- add config to exclude custom files pattern
- support for custom system prompt (via local .md file)
- support working dir level
.hanabi.jsonoverride, smililar to how .npmrc works - streaming mode
- add web server chat bot mode (ie api and web interface)
- improve web server mode (API keys, UX improvements, Update UI mode readme)
- Multi Agent System (WIP)
- local function calling